AI-native systems platform
Ghost AI — Collaborative AI Architecture Workspace
Production-grade AI-powered architecture and workflow builder with realtime collaboration, AI-assisted systems design, and interactive canvas orchestration.
Business question
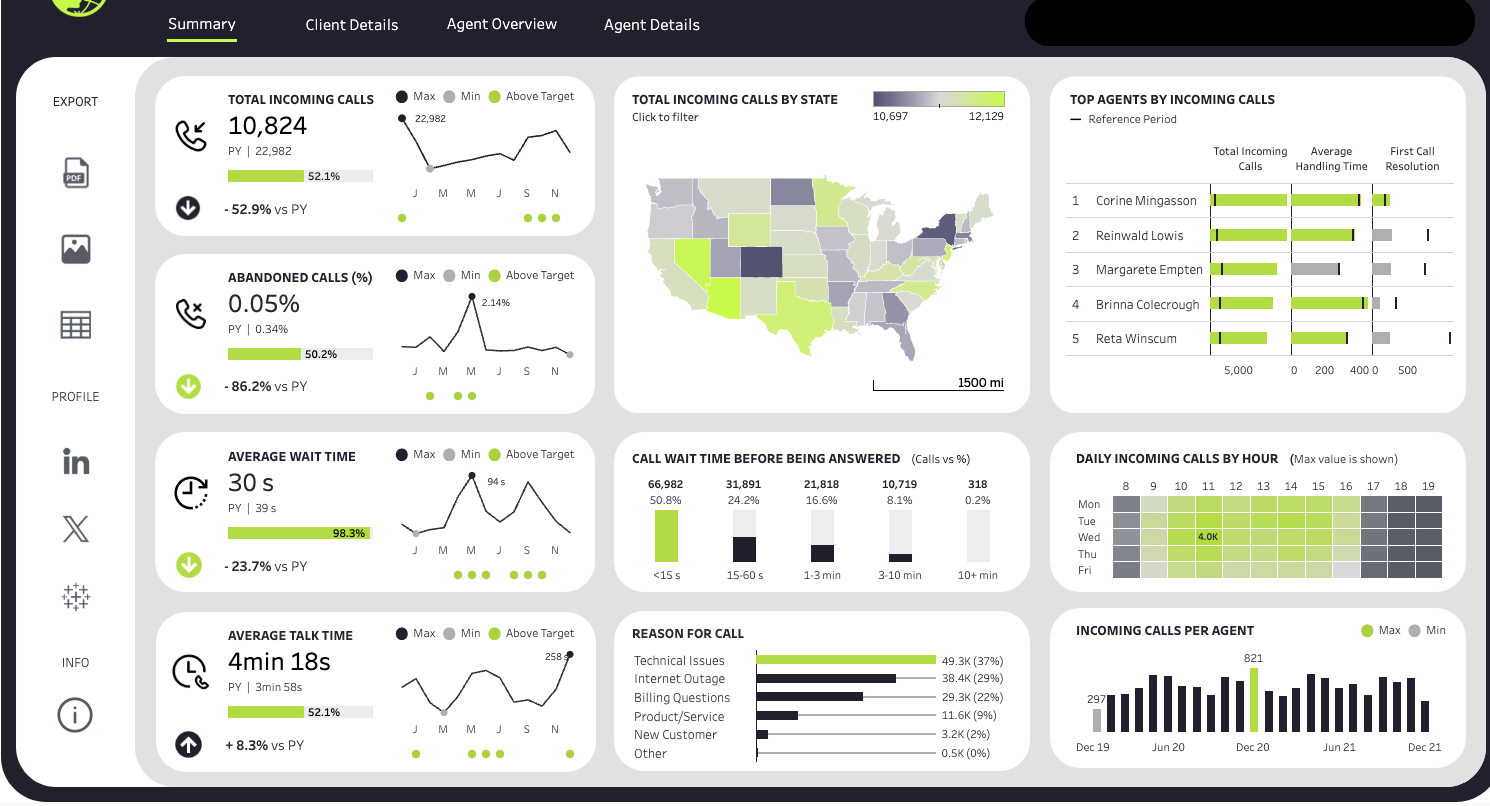
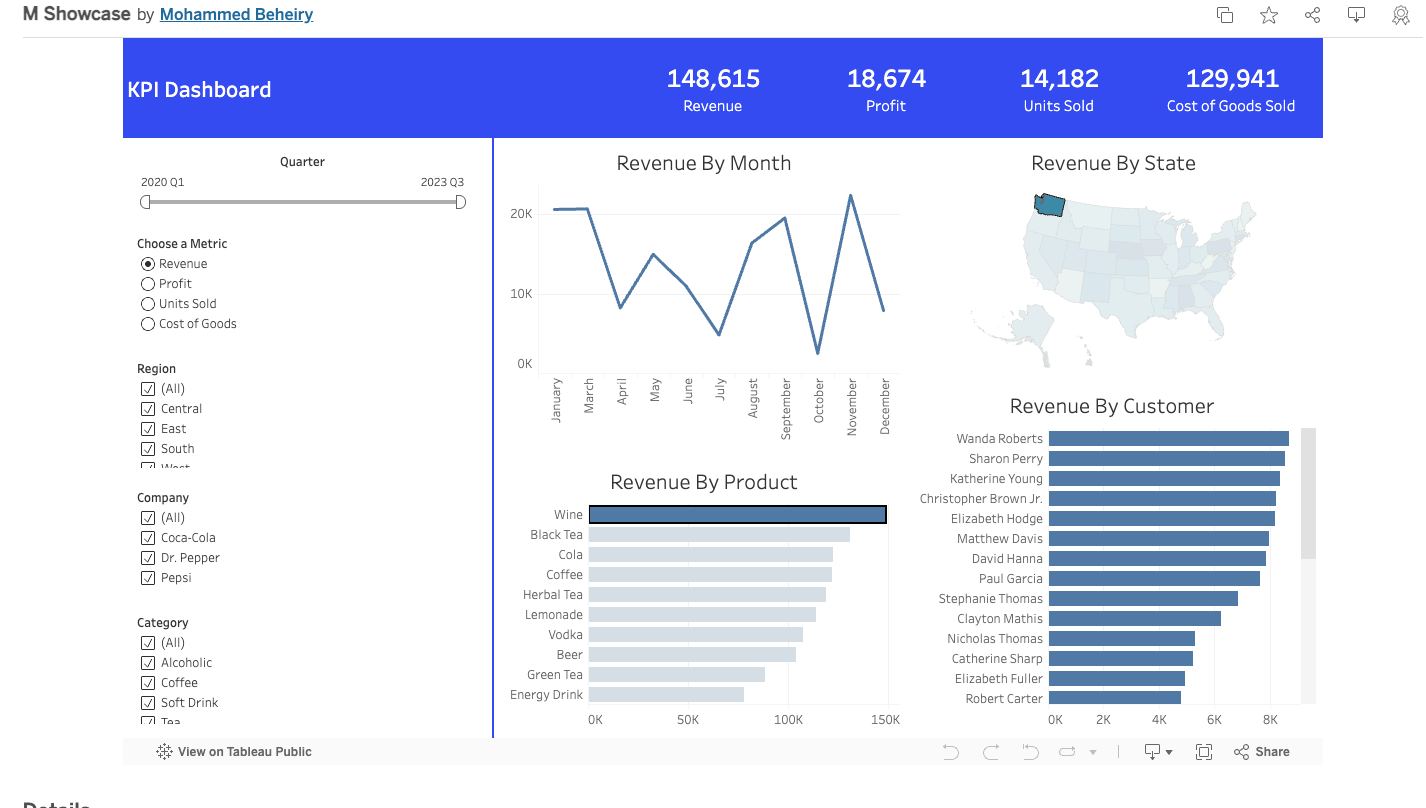
How can product, analytics, and engineering teams design AI systems collaboratively while keeping architecture, workflow orchestration, and implementation context in one place?
Positions Ghost AI as an AI-native product, analytics, and systems orchestration platform for collaborative system design, product/spec generation, background AI workflows, and production debugging.
Next.jsTypeScriptLiveblocksTrigger.devPrismaPostgreSQLOpenRouterReact Flow
View case study 



{kind=link}
{kind=link}